Team –
Welcome back! We’ve been pretty busy on our end, much like everyone else in the world. Recently, we had the opportunity to team up with some staff from VMware and jointly roll out a greenfield VMware Cloud Foundations 5.x instance for a mutual customer. I’m not going to re-create information that’s already available on the web (I’ll link you instead) but if you’re not familiar with what VCF is, it’s vSphere (with or without vSAN), NSX, and a handful of products from the formerly known as vRealize Suite (now known as Aria) bundled together in an environment that is strictly managed and controlled by an appliance known as the SDDC Manager.
This article, and the additional parts that follow, will discuss the issues that we stumbled upon during our deployment. In the future, I also plan to release a series on the entire deployment of VCF.
This part of the series has us with our management domain already partially deployed. The hosts in the management domain are all online and functioning, but that is the extent of the configuration. NSX hasn’t been deployed yet, Application Virtual Networks haven’t been created either, which subsequently means that vRealize hasn’t been rolled out. Once we were at this point, our customer wanted us to start getting a Virtual Infrastructure (VI) domain online. From a physical hardware standpoint, they had eight servers that would make up their first VI domain, and they were already prepped from an OS perspective.
The Issue Shows It’s Face
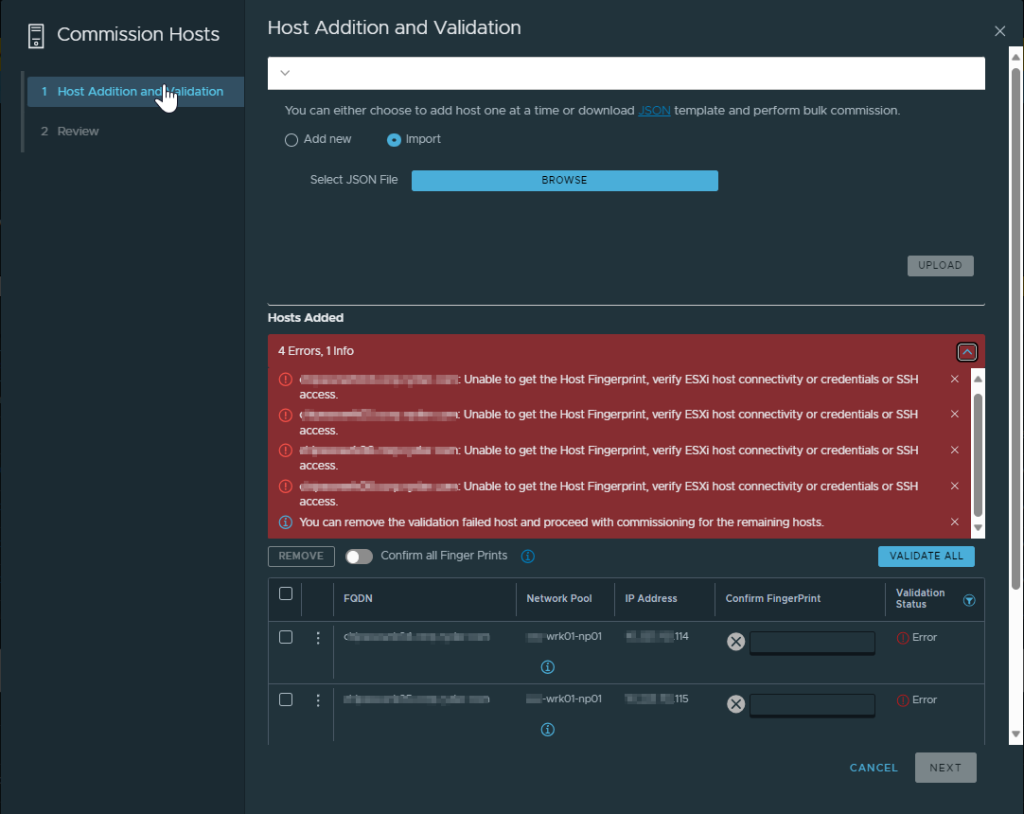
We had the management domain up extremely quickly and were eager to push forward, so when things didn’t go 100% as we wanted to we had to put our troubleshooting hats on. Luckily, the issue wasn’t too complex to resolve. Let’s cut to the chase. When attempted to create the VI domain, it goes through a host verification process to make sure that the server is accessible via SSH, physical NICs are available and configured in a certain way, that the host is not in maintenance mode, and a slew of other things. It presents you with the SSH fingerprint(s) of the host(s) and wants to you validate and confirm them, so you aren’t added some rogue host to your virtualization environment. Well, that was the problem. It couldn’t fetch the SSH fingerprints for some reason (yes, SSH was already enabled and yes, credentials were correct. Yes, we verified this in our troubleshooting steps!)
After the basic levels of troubleshooting, the next logical thing to do was to check the logs. After logging into the SDDC Manager directly, we switched user to root using su, change directory over to the operationsmanager.log file is located, and searched the log for a hostname of a server that was giving us a problem. Low and behold, we have log entries!
su -
cd /var/log/vmware/vcf/operationsmanager
cat operationsmanager.log | grep -i [hostname]
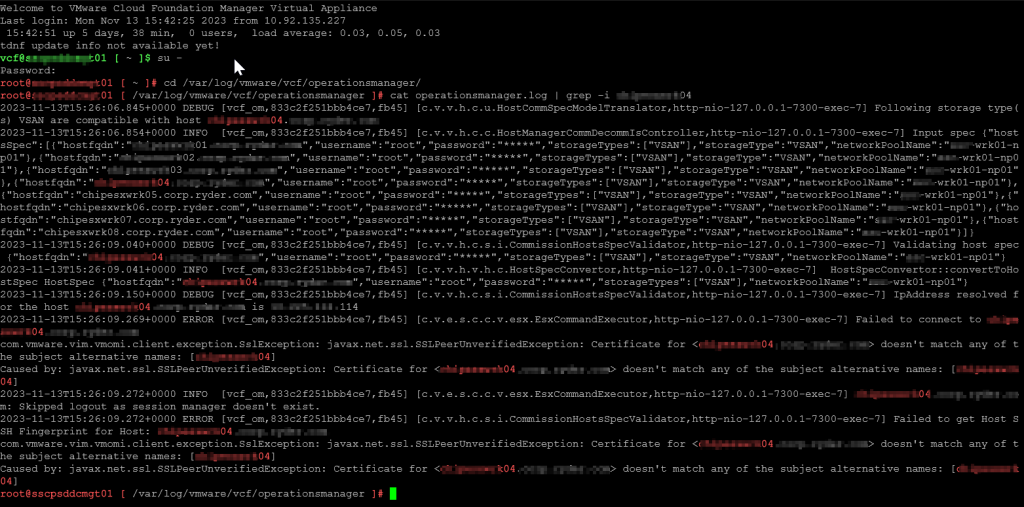
As we can see towards the tail end of the output, it’s complaining that the Subject Alternative Names coded in the certificate of the host do not match the FQDN that we provided. Let’s dig deeper into this and look at the certificate itself. Naturally, we browse to the webGUI of the host, and view its certificate…specifically, it’s SANs.
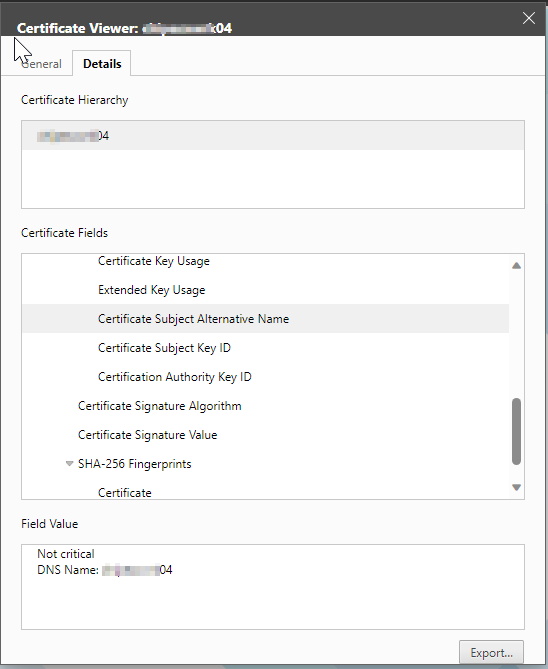
The error is legit. Clearly, the SAN doesn’t match the FQDN of the host, which is how we are communicating with it. How could this have happened? Let’s log into the host and take a peek. After logging into the webGUI, I want to take a look at the hostname configuration, so let’s navigate through the menus to the Default TCP/IP Stack and see what we find.
Click Networking> TCP/IP Stacks > Default TCP/IP Stack > Edit Settings
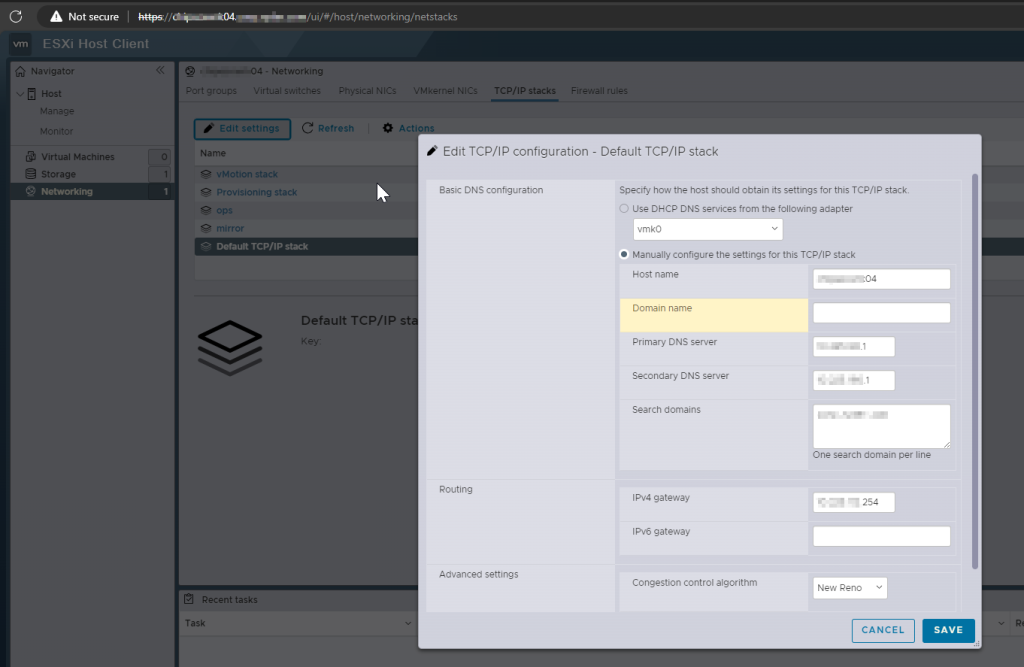
Well, well, well…Looks like what happened was the domain name was left off during initial configuration, which means that the certificate was generate with only the host name as the SAN. Let’s correct it by adding the domain name to the config.
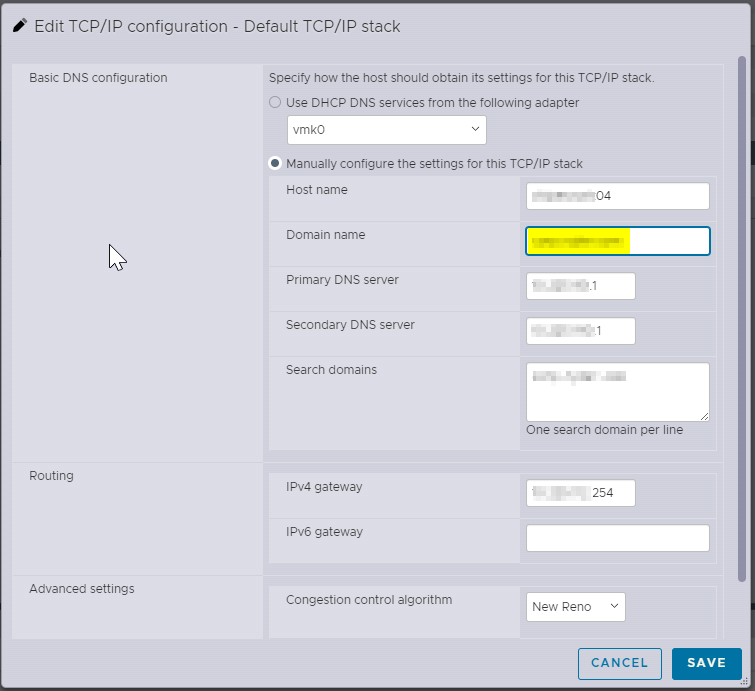
Okay, much better. But that was just a starting point. The certificate still needed to be re-generated. Otherwise, we would have still been sitting in square one. Next, we needed to SSH directly to the host. As I mentioned before, SSH was verified as enabled and we haven’t rebooted, so the service was still running. We re-generated the host certificates by running:
/sbin/generate-certificates
followed by:
/etc/init.d/hostd restart && /etc/init.d/vpxa restart
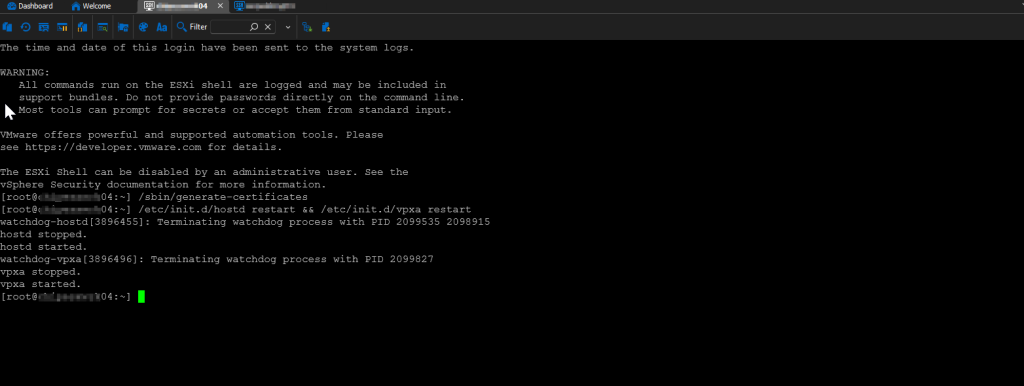
This restarted the appropriate services so that the new certificate would be consumed, which was verified by refreshing the webGUI’s page and viewing the certificate again.
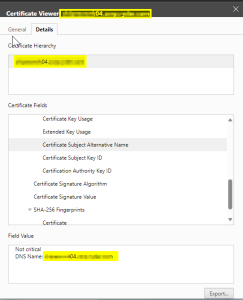
Everything looked good so we repeated the process for the remaining hosts. After that, there was no reason to believe that the VCF validations would continue to fail, so we tried again.
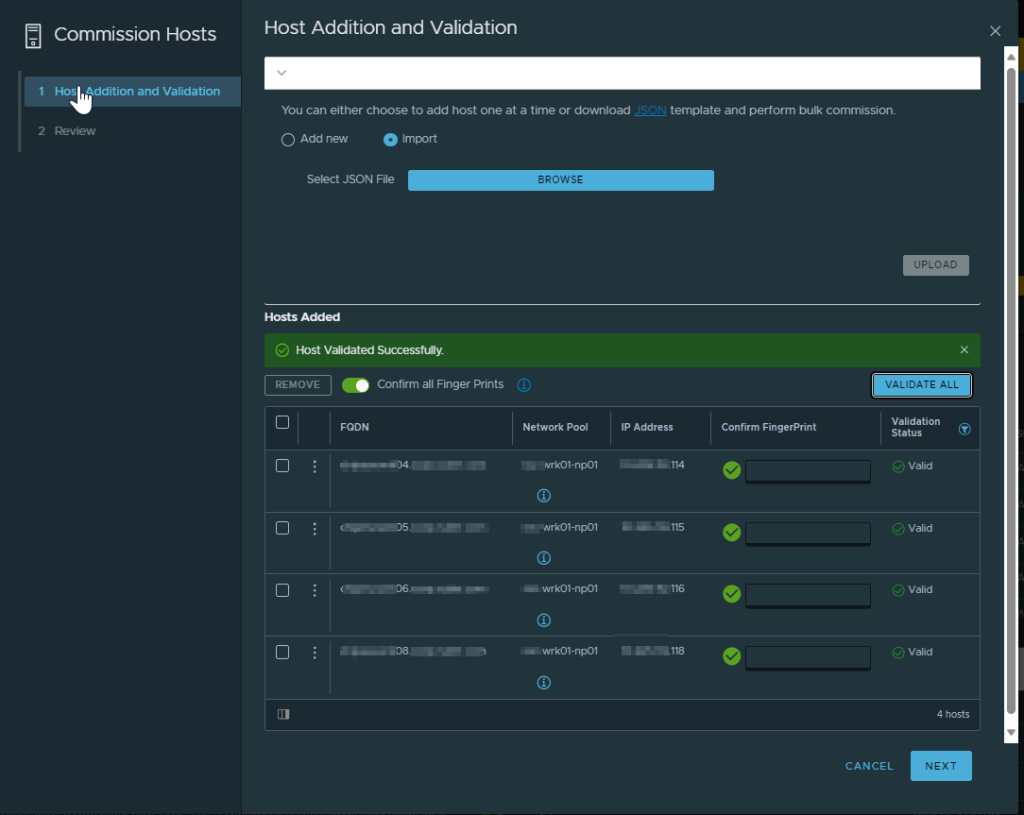
Successful! The validation completed and the first VI domain got created using the formerly problematic hosts.
Conclusion
I hope this article proves to be helpful to someone with their deployment of VCF. Thanks for reading. If you enjoyed the post, make sure you check us out at dirmann.tech and follow us on LinkedIn, Twitter, Instagram, and Facebook!

Paul Dirmann (vExpert PRO*, vExpert***, VCIX-DCV, VCAP-DCV Design, VCAP-DCV Deploy, VCP-DCV, VCA-DBT, C|EH, MCSA, MCTS, MCP, CIOS, Network+, A+) is the owner and current Lead Consultant at Dirmann Technology Consultants. A technology evangelist, Dirmann has held both leadership positions, as well as technical ones architecting and engineering solutions for multiple multi-million dollar enterprises. While knowledgeable in the majority of the facets involved in the information technology realm, Dirmann honed his expertise in VMware’s line of solutions with a primary focus in hyper-converged infrastructure (HCI) and software-defined data centers (SDDC), server infrastructure, and automation. Read more about Paul Dirmann here, or visit his LinkedIn profile.
Share this article on social media: